
This is the Web home of the Uyghur Light Verbs Project, a project at the University of Kansas directed by Prof. Arienne M. Dwyer and funded by the National Science Foundation.
The project is now reaching its end; we currently make the following technical information available:
The original documents were transcribed by a variety of collaborators, using varying orthographic conventions, usually in Transcriber, Open Office, and Microsoft Word and/or Excel.
In the initial stages of the project, annotators broke the documents into sentences (or sentence-like units, often called s-units for short) and supplied line-by-line annotation (segmentation, part-of-speech tagging, morpheme glosses) in a line-oriented format, working within Open Office.
In 2011, we developed an XML version of this line-oriented format (see description of PixCor below) and converted existing annotated data into it. For new documents to be annotated, conversion from a word processing format to XML ('XMLification') is the first step in preparing documents; supplying a header with document-specific metadata is the second step.
Using XForms, we developed an interactive Web interface for annotation, which allowed the annotators to focus on linguistic issues and not on managing the XML markup. Later elaborations of the XForms interface provided automatic alignment checking to make sure that each segment has a part of speech and an interlinear gloss.
In 2011, we developed a second XForms interface, for the creation of the metadata header.
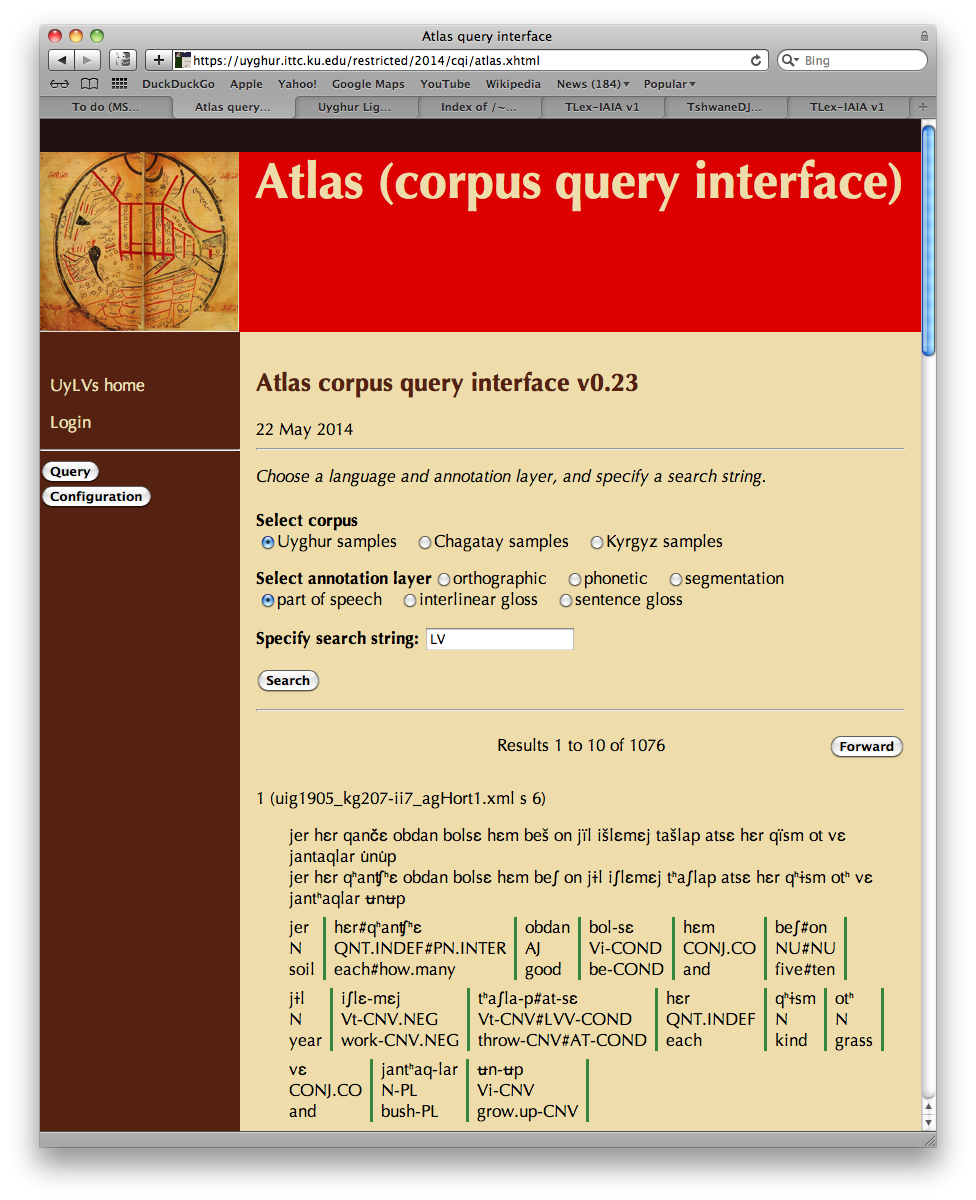
Completed documents and documents in progress can be searched by means of a (project-internal) corpus query interface.
After final checking, selected documents are made public as part of the UyLVs demonstration corpus.
Annotators have access to two query interfaces.
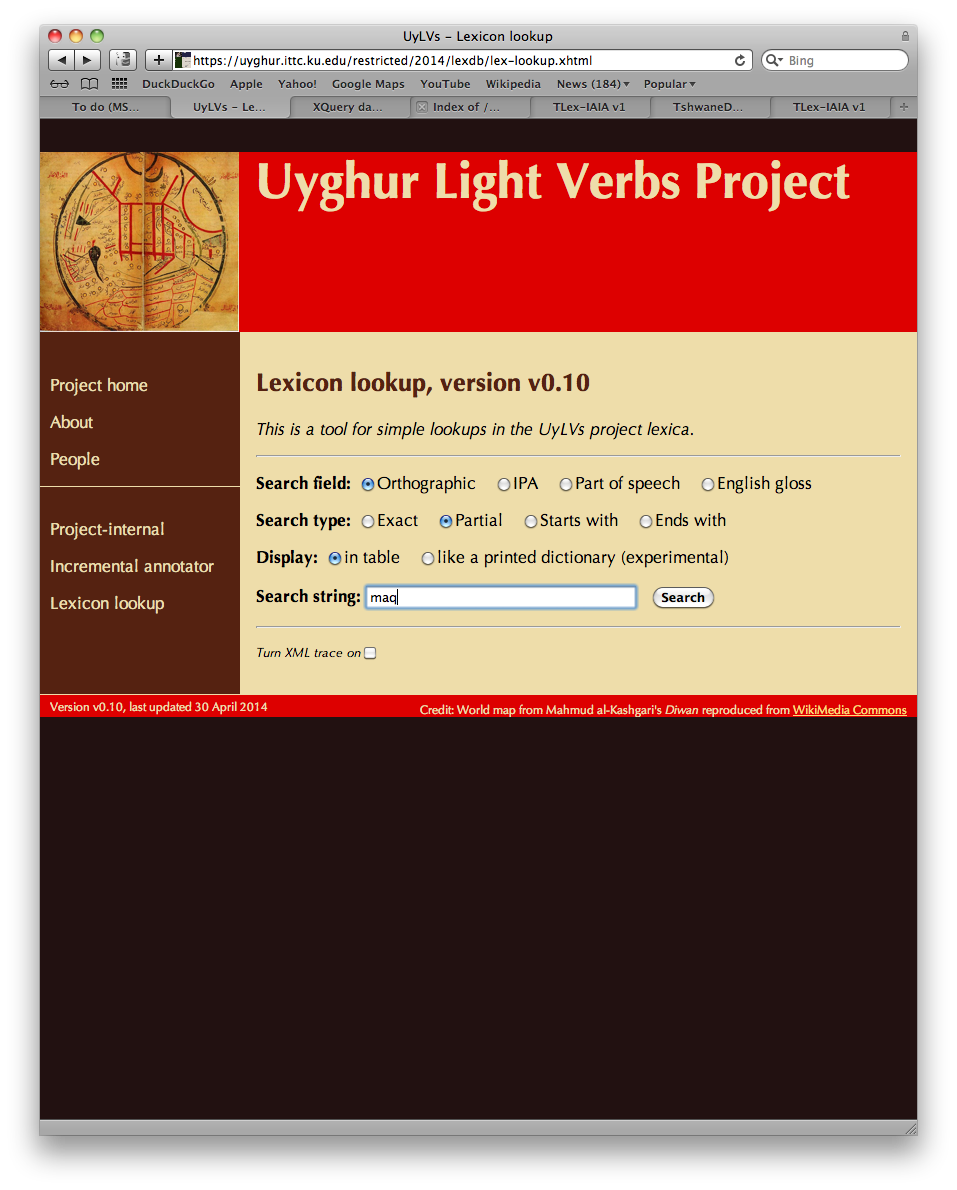 In one query interface, the annotator can search in the lexical
database and part-of-speech-tag database built by the project,
to find entries for morphemes appearing in a
sentence being annotated. The search screen
allows searching on the orthographic form,
the IPA transcription,
the part of speech information, or the gloss for the
morpheme, with exact string match, partial string match,
prefix, and suffix matching all as options.
In one query interface, the annotator can search in the lexical
database and part-of-speech-tag database built by the project,
to find entries for morphemes appearing in a
sentence being annotated. The search screen
allows searching on the orthographic form,
the IPA transcription,
the part of speech information, or the gloss for the
morpheme, with exact string match, partial string match,
prefix, and suffix matching all as options.
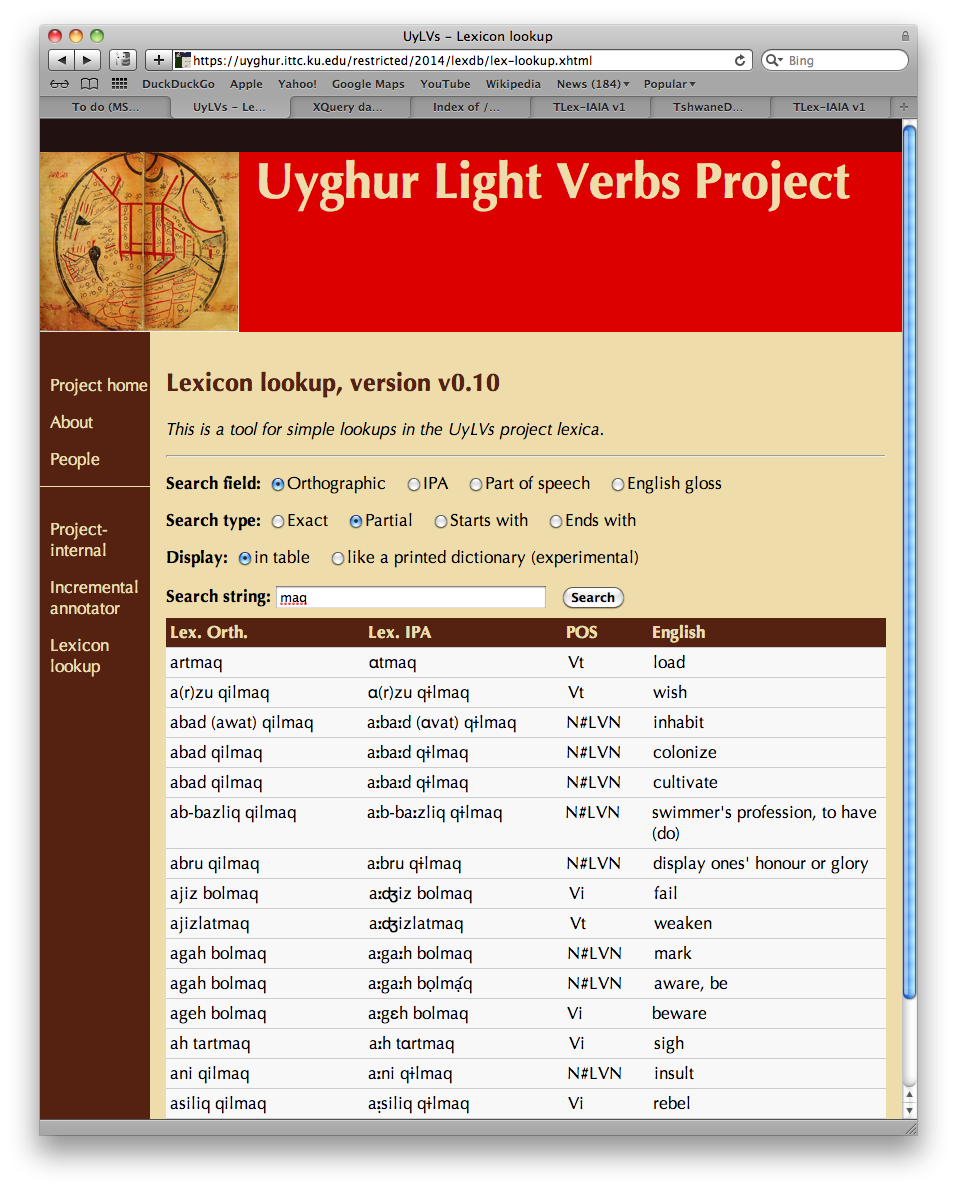
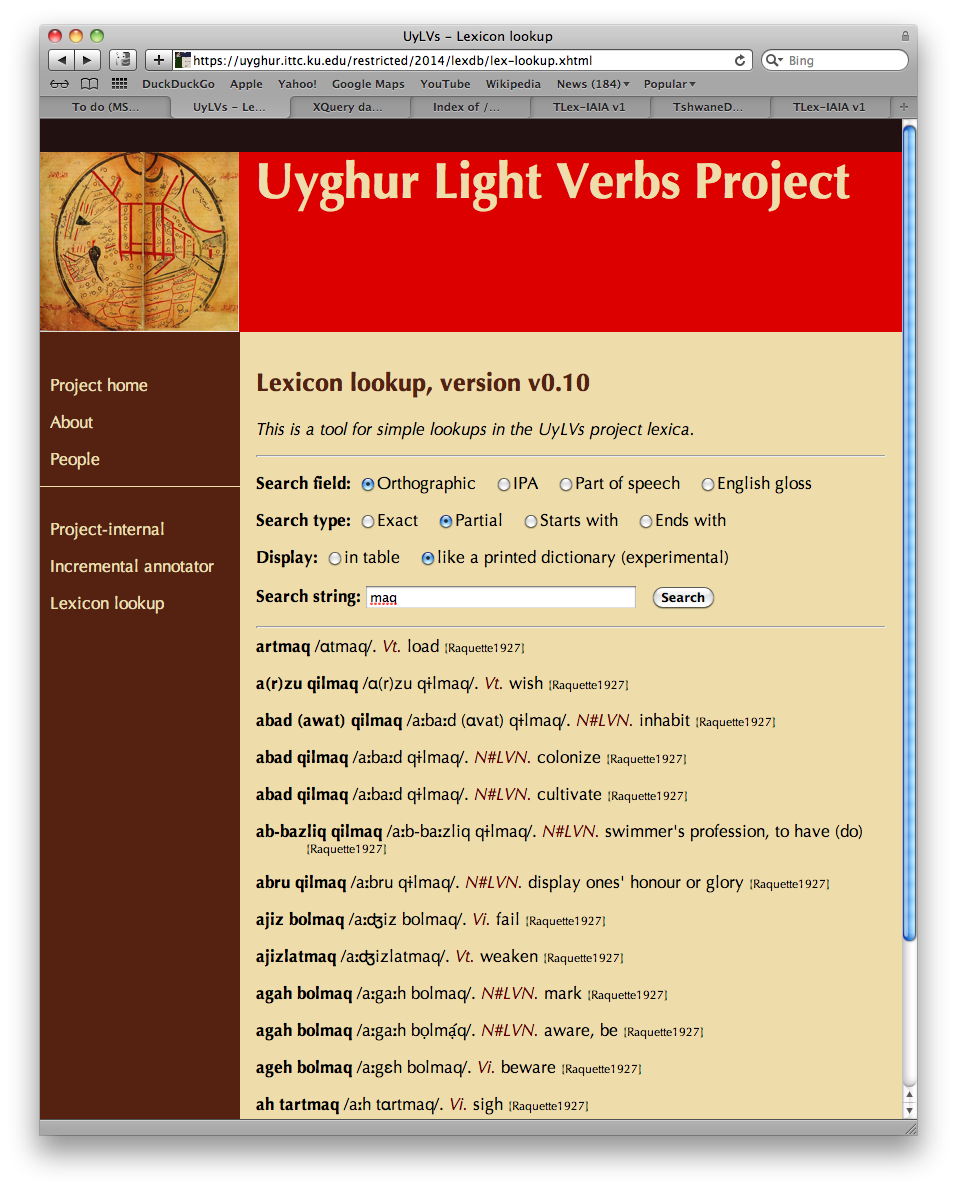 A search can be displayed either in tabular form or in
a prose format. Different annotators express different
preferences regarding the display format; since the formatting
is controlled by an XSLT stylesheet invoked by XForms, it is
easy to leave the choice between tabular and prose display
to the annotator.
A search can be displayed either in tabular form or in
a prose format. Different annotators express different
preferences regarding the display format; since the formatting
is controlled by an XSLT stylesheet invoked by XForms, it is
easy to leave the choice between tabular and prose display
to the annotator.
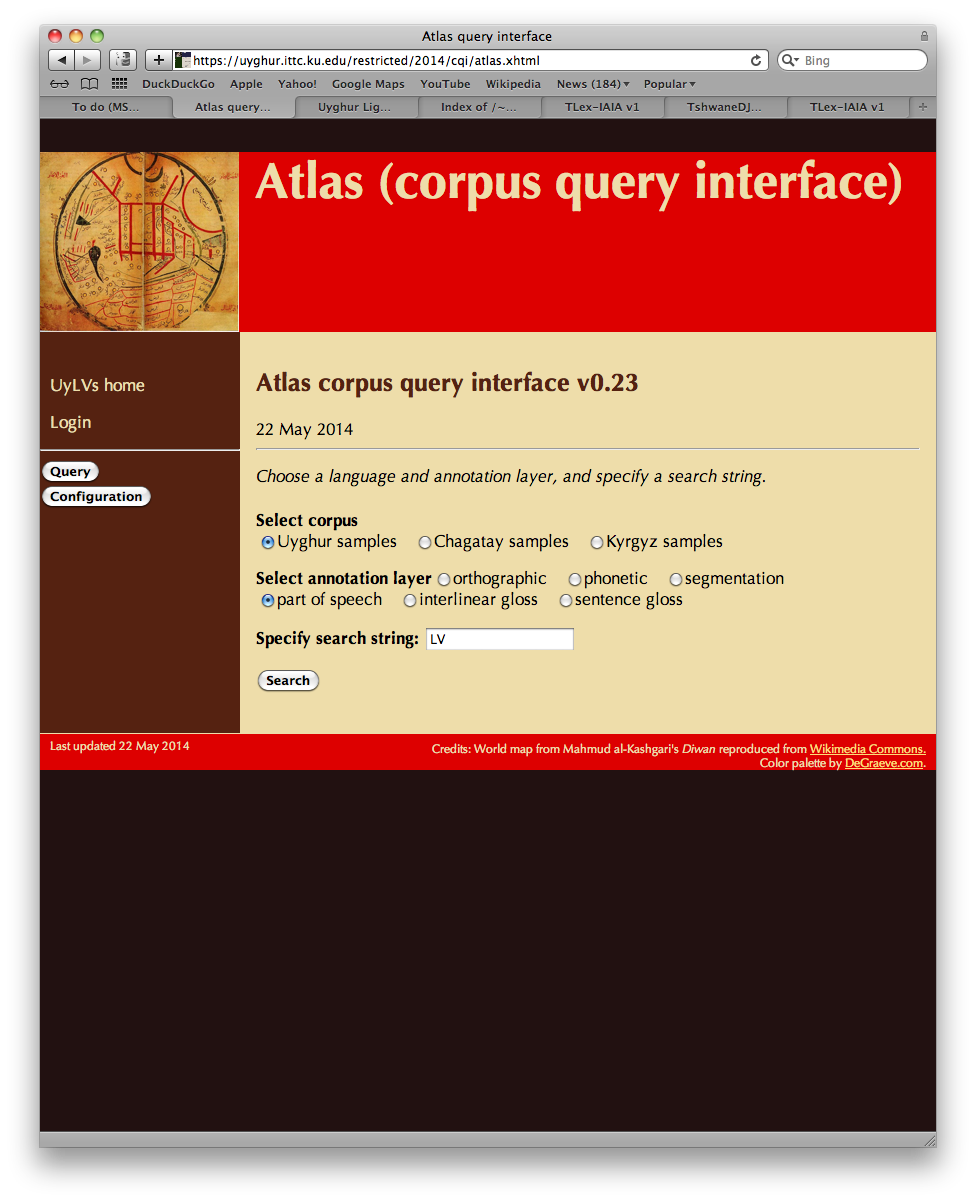
A second interface allows for searching in the corpus of annotated material. Here, the initial search screen allows a choice of corpus (Uyghur, Chagatay, Kyrgyz) and annotation layer (orthographic form, segmentation, part-of-speech, interlinear gloss, or sentence gloss). The result of any corpus query is a set of s-units; the hits are shown a few at a time, in essentially the same format as for the public read-only display of the texts.
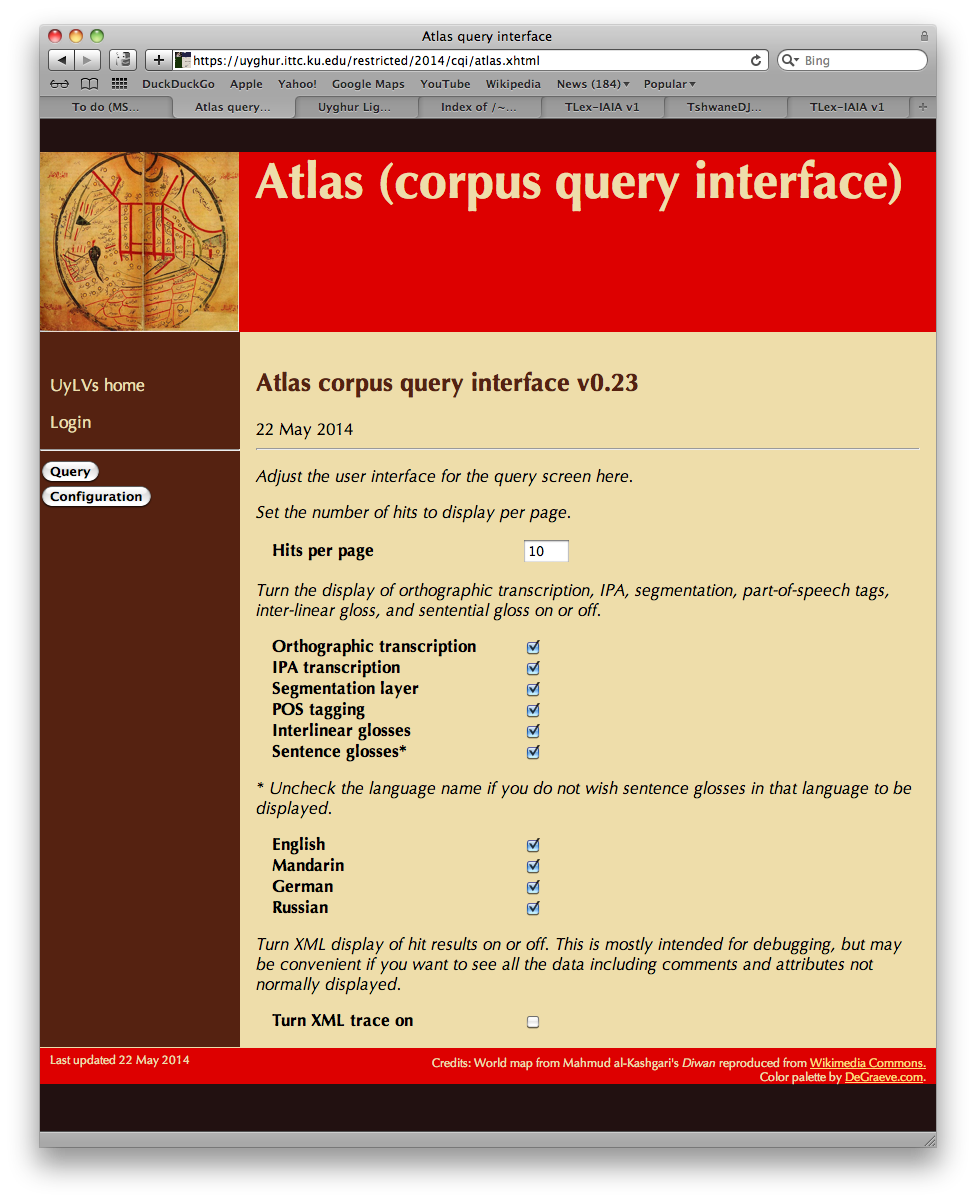
In a configuration screen, the user can control some aspects of the display: how many results to display per page, and whether to display or hide the orthographic transcription, the IPA transcription, the segmentation layer, the part-of-speech layer, the interlinear glosses, and the sentence glosses. If sentence glosses are being displayed, the user can additionally filter them by language (e.g. to exclude glosses in a language the user does not find helpful).
An XQuery engine (BaseX) is used as a back end for both query interfaces. The user interface is managed by the XSLTForms implementation of XForms; the query is sent to the server as a simple XML document. A PHP program on the server acts as an intermediary between the user interface and the server. By parsing the query itself and discarding queries that violate the constraints of the interface, the PHP program helps to prevent XQuery injection attacks.
The corpus and lexicon query interfaces are currently only available to participants in the project, not publicly.
A paper originally given in July 2013 at DH 2013, in Lincoln, Nebraska, ("XQuery databases for linguistic resources in the IAIA and UyLVs projects) is available. It discusses some of the design challenges faced by the project in developing query interfaces and making them public.
UyLVs corpus texts are encoded in an XML vocabulary we call Pixcor (‘project-internal XML corpus format’), version 1.1. A DTD and documentation in the form of a TEI tag-set description document are available.
Initial plans called for Pixcor to be a temporary solution only, and for a systematic document analysis process to be performed, leading to a new vocabulary (and new versions of all Pixcor-aware tools), perhaps a customization of TEI. This plan has been overtaken by events.
The lexical databases created by the UyLVs project are encoded in a project-specific customization of the lexicon markup used by the commercial dictionary software TshwaneLex. (We are grateful to TshwaneDJe Human Language Technology for making Tshwanelex available at a discounted rate to us and to other projects working on endangered languages.) The DTD for Pixlex is publicly available.
Credit: Painting of Mahmud al-Kashgari © 1981 by Ghazi Emet.